Async
Asynchronous Functions¶
OpenFaaS enables long-running tasks or function invocations to run in the background through the use of NATS JetStream or NATS Streaming. This decouples the HTTP transaction between the caller and the function.
- The HTTP request is serialized to NATS through the gateway as a "producer".
- The queue-worker acts as a subscriber and deserializes the HTTP request and uses it to invoke the function directly
The asynchronous workflow can have a longer, separate timeout compared with synchronous timeout on the gateway.
Why might you want to use an asynchronous invocation?
You're working with a partner's webhook. They send you data, but if you don't send a HTTP 200 OK within 1 second, they assume failure and retry the message. This works well if your function can complete in less than a second on every invocation, but if there's any risk that it can't, you need another solution. So you will give your partner a URL to the asynchronous function URL instead and it will reply within several milliseconds whilst still processing the data.
Other popular use-cases include:
- Batch processing and machine learning
- Resilient data pipelines
- Long running jobs
See these blog posts for examples of asynchronous patterns in practice:
- Exploring the Fan out and Fan in pattern with OpenFaaS
- Generate PDFs at scale on Kubernetes using OpenFaaS and Puppeteer
- How to process your data the resilient way with back pressure
- The Next Generation of Queuing: JetStream for OpenFaaS
Synchronous vs asynchronous invocation¶
-
Sync
A synchronous invocation of a user requesting a PDF would be as follows, where connections are established between each component from the beginning to the end of the invocation.
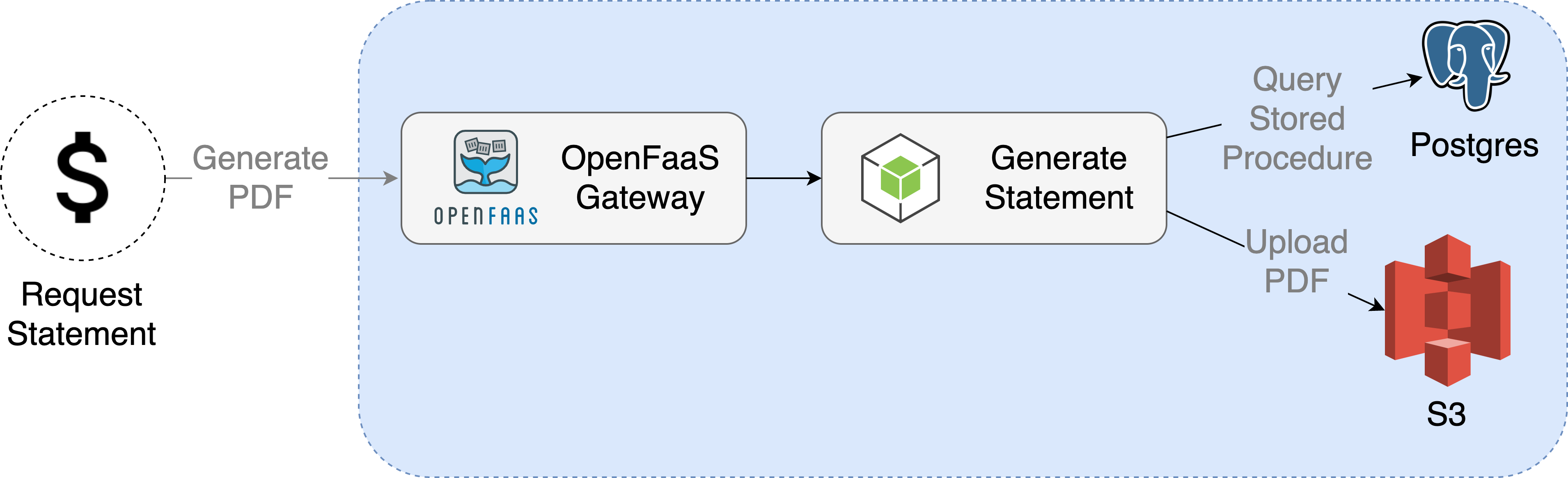
If the whole process takes less than a few seconds, this may be the ideal approach, given that it's simple to implement.
-
Async
An asynchronous invocation of a user requesting a PDF would be as follows: an initial connection is formed to the gateway, the user's request is serialized to a queue via the queue-worker and NATS. At a later time, the queue-worker then dequeues the request, deserializes it and makes it to the function - either directly or via the gateway using a synchronous call.
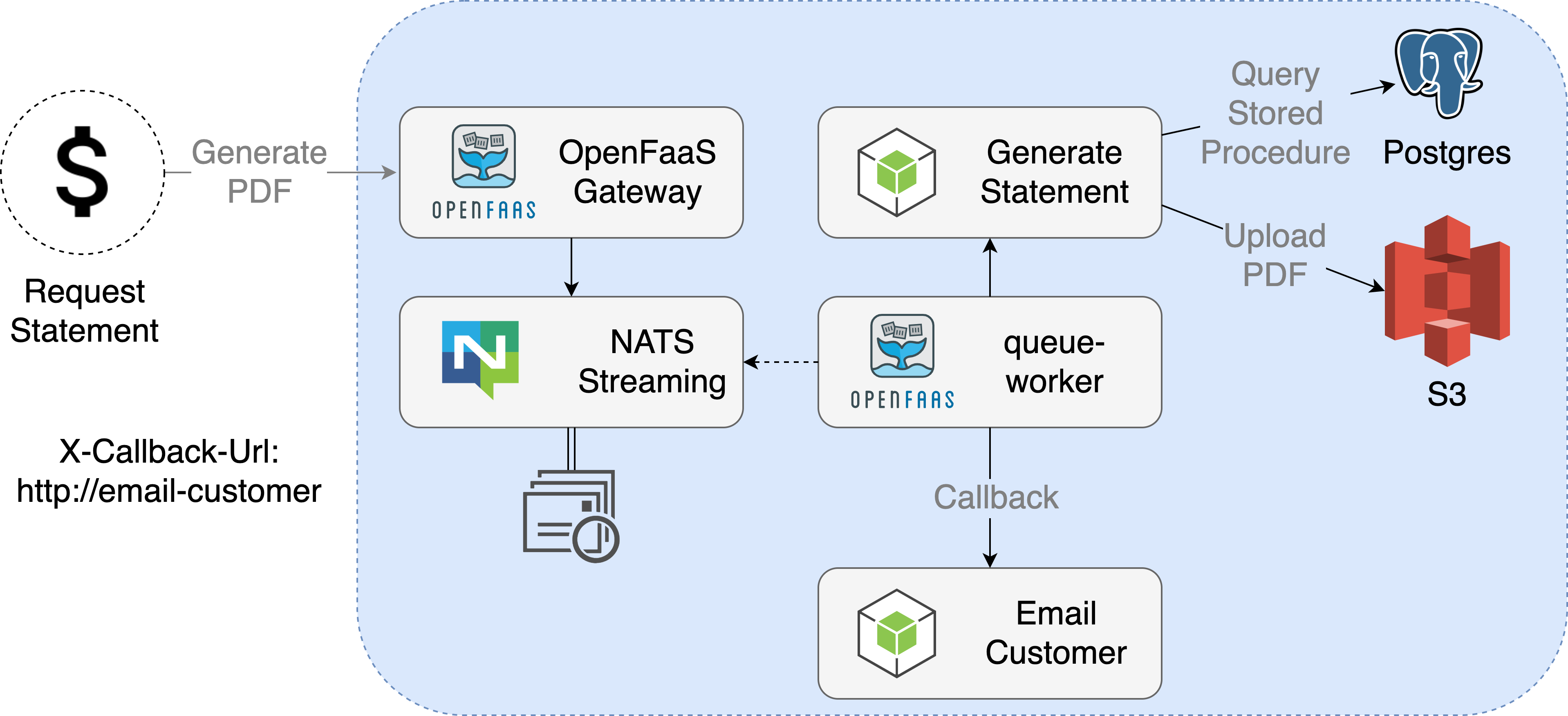
This is beneficial if there are for instance 100 requests that all take 2 minutes to execute. It means the client / caller needs to wait only for a few milliseconds.
How it works¶
Any function can be invoked asynchronously by changing the route on the gateway from /function/<name> to /async-function/<name>. A 202 Accepted message will be issued in response to asynchronous calls.
Note: that asynchronous invocations do not make sense with a HTTP
GETverb since they are queued and deferred, there is nothing toGET. For this reason, a HTTPPOSTis required.
If you would like to receive a value from an asynchronous call you should pass a HTTP header with the URL to be used for the call-back.
$ faas invoke figlet -H "X-Callback-Url=https://request.bin/mybin"
It will pass back the X-Call-Id you had when you sent the initial request.
You can use netcat to check the Call Id during invocation:
$ curl http://127.0.0.1:8080/async-function/figlet \
--data "Hi" \
--header "X-Callback-Url: http://<your-ip>:8888"
$ nc -l 8888
HTTP/1.1 200 OK
Content-Length: 174
Content-Type: application/x-www-form-urlencoded
Date: Tue, 04 Dec 2018 09:24:55 GMT
X-Call-Id: eb8283f5-1679-48e0-afec-194544b054aa
X-Duration-Seconds: 0.002885
X-Start-Time: 1543915495384346700
_ _ _ _
| | | | ___| | | ___
| |_| |/ _ \ | |/ _ \
| _ | __/ | | (_) |
|_| |_|\___|_|_|\___/
Alternatively you can specify another asynchronous or synchronous function to run instead.
Cancel async invocations¶
Sometimes you might need to cancel an ongoing or queued invocation. Asynchronous invocations can be cancelled by making an HTTP DELETE request to /async-function/<call-id>. The call id is the X-Call-Id header that was returned when submitting the async invocation.
$ curl -i \
-X DELETE \
http://127.0.0.1:8080/async-function/ee7fcaeb-82b7-4834-b677-45005c5f0b1b
A 202 Accepted message will be issued if the request is successful.
Reasons why you might need to cancel an async request:
- Cancel long running tasks.
- Cancel failing invocations, e.g due to an invalid payload, that would otherwise be retried by the queue-worker until the max retry limit is reached.
- Cancel all invocations that are part of a batch if one fails.
Making an asynchronous call from another function¶
You cannot use the address 127.0.0.1 when calling the gateway from within a function, because this refers to the function's container and local network, not the gateway's.
Instead, use the following URL: http://gateway.openfaas.svc.cluster.local:8080/async-function/NAME
The suffix minimises unnecessary DNS lookups, so increases performance. This suffix is usually svc.cluster.local, however, this may vary between clusters.
For a synchronous call, use http://gateway.openfaas.svc.cluster.local:8080/function/NAME.
The same URL applies for any X-Callback-Url that you wish to pass.
Configuration & Limits¶
There are limits for asynchronous functions, which you should understand before using them:
- Timeouts - the timeout for any asynchronous function must "agree" with all other timeouts within the system, including the gateway and the function.
- Concurrency / parallelism - the amount of function invocations processed at any one time.
- Named queues - by default there is one queue, but additional queues can be added. Each named queue can have its own timeout and concurrency.
- Payload size - the maximum size is configured to be 1MB. The limit is defined by NATS, but can be changed. Use a database, or S3 bucket for storing large payloads, and pass an identifier to function calls.
- Retries - asynchronous invocations can be retried automatically when a function returns an error. Retries use an exponential back-off algorithm. See: retries.
The maximum execution time for an asynchronous function is controlled by the gateway's upstream_timeout and the function's exec_timeout. See Extended timeouts. It is not set by the NATS ack_wait value.
ack_wait (default 60s) is a NATS-level heartbeat that lets the JetStream server detect a dead queue-worker and redeliver the message. While a function is in flight, the queue-worker extends the lease automatically, so the function can run for as long as the gateway and function timeouts allow (effectively indefinitely). Leave ack_wait at its default. Increasing it does not extend how long your function may run; it only delays redelivery if a queue-worker dies mid-invocation.
Parallelism¶
OpenFaaS CE supports max_inflight of 1, OpenFaaS Pro supports a custom value.
By default there is one queue-worker replica deployed which is set up to run a single task of up to 30 seconds in duration.
You can increase the parallelism by setting the queue worker's "max_inflight" option to a value greater than one. This will cause the queue-worker to concurrently receive up to max_inflight many messages and simultaneously invoke their corresponding functions. Should you wish to restrict concurrency for certain functions, please make use of dedicated queues and separate these functions accordingly.
Additional replicas of the queue-worker can also be added, such that the total async concurrency for a cluster will be: max_inflight * (number of queue-worker replicas).
So a value of max_inflight 100 and 1 queue-worker, will mean a system-wide async concurrency of 100. A value of max_inflight 100 and 3 queue-workers, will mean a system-wide async concurrency of 300.
Kubernetes users can tune this in the values.yaml file of the openfaas helm chart. faasd users should edit the docker-compose.yml file.
The official eBook for OpenFaaS has more details on the async system in OpenFaaS. See also: Training
Dedicated queues¶
OpenFaaS Pro supports a single shared queue for asynchronous requests. OpenFaaS Enterprise supports dedicated queues per function.
Asynchronous requests are processed by the queue-worker component using a single topic (faas-request), for most use-cases this will be sufficient if most of your functions take a similar amount of time to execute. A problem may arise when you have a mixture of slow and fast running requests within the same single queue. A single slow task can hold up all the other requests and this is because the queue has FIFO semantics - first in, first out.
To use multiple queues you need to do two things:
1) Annotate your functions with a com.openfaas.queue queue or (topic) name
Imagine that your new queue is called slow-queue, you would run the following:
faas-cli store deploy figlet \
--annotation com.openfaas.queue=slow-queue
2) Create a queue-worker for the new queue name
You now need to deploy a new queue-worker for the queue name, so that it can subscribe to messages and invoke functions without affecting the default queue.
Follow the instructions in the dedicated Helm chart for additional queue-workers.
Then, you can invoke the function asynchronously and the queue's name will be looked up by the gateway automatically.
faas-cli invoke --async figlet <<< "OpenFaaS"
Verbose Output¶
The Queue Worker component enables asynchronous processing of function requests. The default verbosity level hides the message content, but this can be viewed by setting write_debug to true when deploying.
Callback request headers¶
The following additional request headers will be set when invoking the callback URL:
| Header | Description |
|---|---|
| X-Call-Id | The original function call's tracing UUID |
| X-Duration-Seconds | Time taken in seconds to execute the original function call |
| X-Function-Status | HTTP status code returned by the original function call |
| X-Function-Name | The name of the original function that was executed |
| User-Agent | The queue-worker's user-agent string including the version i.e. queue-worker/0.10.0 |
| X-Retry | The number of times the original function was retried on the queue, if applicable |
| X-Retry-Max | The maximum number of retries allowed for the original function or queue-worker (whichever is set) |
If the X-Retry value is the same as the X-Retry-Max value, then the function has been retried the maximum number of times and will not be retried again.